Podcamp Halifax Scheduling
One of my favourite Halifax tech events. I attended my first year, gave a talk in each of my next two years (one on A/B testing and another on Piwik, a Google Analytics alternative), and then decided to join the organizing committee for my fourth year.
I was put in charge of the scheduling, a seemingly simple but very important task. I'm really proud of the final PDF, but how did it all come together?
My notion was to apply a data-driven approach to scheduling the talks, making sure that popular talks didn't overlap each other, and didn't overload the capacity of the room they were assigned to.
First was to get a list of the talks that would be presented. Our speaker liaison team did a great job promoting the conference, as they always do, and attracted a wide variety of quality presentations. Next we needed to gauge audience response to the schedule. And the data analysis began.
 The survey was simple but effective: It had six dropdown boxes, populated with the names of the talks to be presented at the conference. A link to the website where full details could be accessed was also provided. Respondents simply selected the six talks they were most likely to attend.
The survey was simple but effective: It had six dropdown boxes, populated with the names of the talks to be presented at the conference. A link to the website where full details could be accessed was also provided. Respondents simply selected the six talks they were most likely to attend.
On the backend, their entries were fed anonymously into rows on a spreadsheet. Tabulation was also simple: Being in the first slot gave a talk six points, the second slot meant five points, and so on.
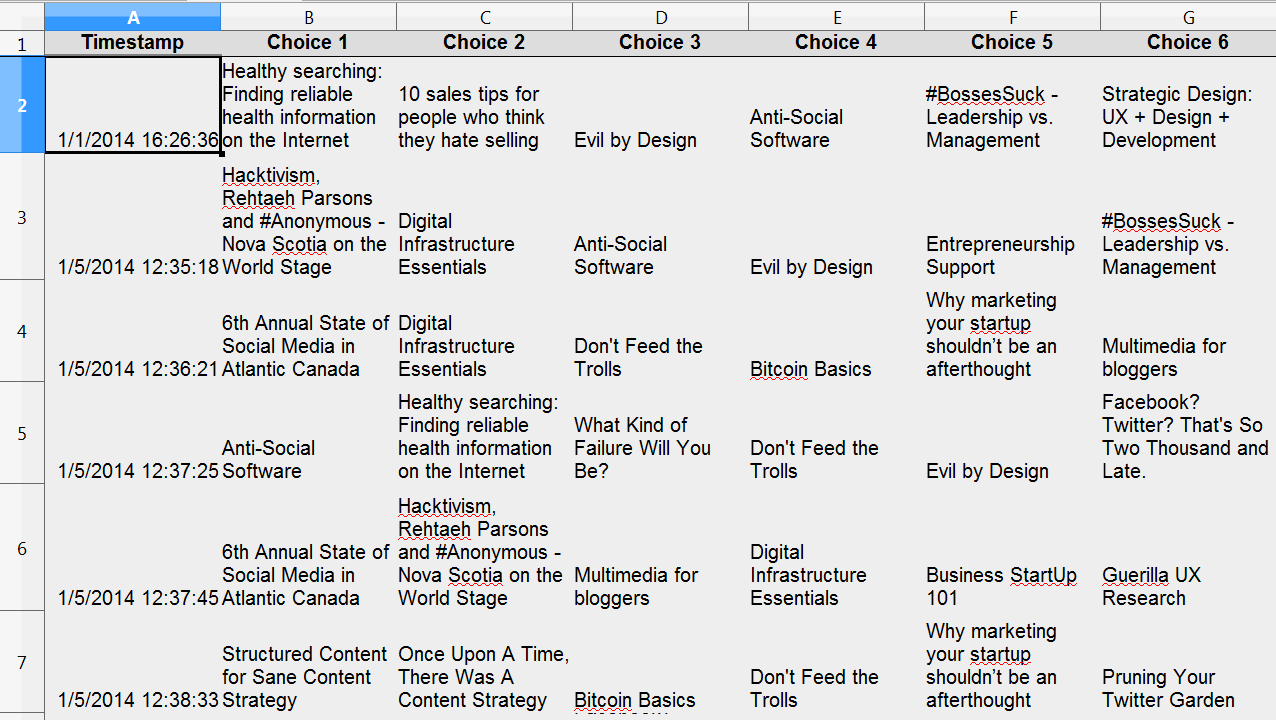 Once all the responses were processed, we had two very important points of data:
Once all the responses were processed, we had two very important points of data:
- a figure for maximum projected attendance at each talk
- the aggregate priority of each talk
Using this data, we knew which talks were going to be popular, and approximately how many people were going to be attending them. This allowed us to avoid scheduling popular talks against each other, and made sure everyone who showed up had a seat.
Success!